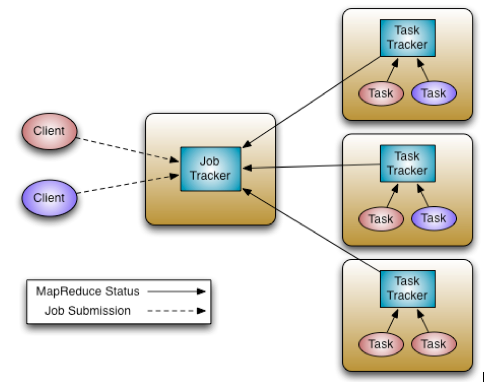
The Hadoop 0.x MapReduce system composed of JobTracker and
TaskTrackers.
The JobTracker is responsible for resource management, tracking
resource usage and job life-cycle management, e.g. scheduling job tasks,
tracking progress, providing fault-tolerance for tasks.
The TaskTracker is the per-node slave for JobTracker, takes orders
from the JobTracker to launch or tear-down tasks, and provides task
status information to the JobTracker periodically.
For those years, we are benefited from the MapReduce framework, it's
the most successful programming model in the big data world.
But MapReduce is not everything, we need to do graph processing, or
real-time stream processing, since Hadoop is essentially batch oriented,
we have to look for other systems to do those work.
And the hadoop community made a huge change.
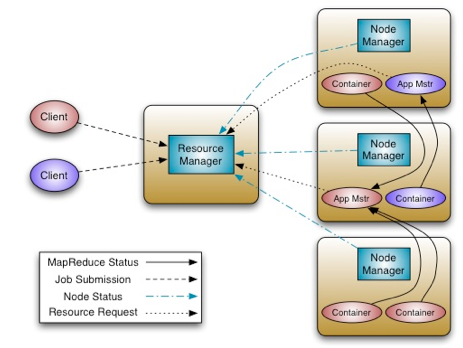
The Hadoop YARN
The fundamental idea of YARN is to split up the two major
responsibilities of the JobTracker i.e. resource management and job
scheduling/monitoring, into separate daemons: a global ResourceManager
(RM) and per-application ApplicationMaster (AM).
The ResourceManager is responsible for allocating resources to the
running applications.
The NodeManager is a per-machine slave, works on launching the
application's containers, monitoring the resource usage, and reporting
them to the ResourceManager.
The ApplicationMaster is a per-application framework, which runs as a
normal container, responsible for negotiating appropriate resource
containers from ResourceManager, tracking their status and monitoring
for progress.
14/02/20 22:50:59 INFO distributedshell.Client: Initializing Client 14/02/20 22:50:59 INFO distributedshell.Client: Running Client 14/02/20 22:50:59 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 14/02/20 22:50:59 INFO distributedshell.Client: Got Cluster metric info from ASM, numNodeManagers=1 14/02/20 22:50:59 INFO distributedshell.Client: Got Cluster node info from ASM 14/02/20 22:50:59 INFO distributedshell.Client: Got node report from ASM for, nodeId=192.168.0.102:52786, nodeAddress192.168.0.102:8042, nodeRackName/default-rack, nodeNumContainers0 14/02/20 22:50:59 INFO distributedshell.Client: Queue info, queueName=default, queueCurrentCapacity=0.0, queueMaxCapacity=1.0, queueApplicationCount=0, queueChildQueueCount=0 14/02/20 22:50:59 INFO distributedshell.Client: User ACL Info for Queue, queueName=root, userAcl=SUBMIT_APPLICATIONS
...
14/02/20 22:50:59 INFO distributedshell.Client: Max mem capabililty of resources in this cluster 2048 14/02/20 22:50:59 INFO distributedshell.Client: Copy App Master jar from local filesystem and add to local environment 14/02/20 22:51:00 INFO distributedshell.Client: Set the environment for the application master 14/02/20 22:51:00 INFO distributedshell.Client: Setting up app master command 14/02/20 22:51:00 INFO distributedshell.Client: Completed setting up app master command$JAVA_HOME/bin/java -Xmx10m org.apache.hadoop.yarn.applications.distributedshell.ApplicationMaster --container_memory 10 --num_containers 2 --priority 0 --shell_command date --shell_args -u 1><LOG_DIR>/AppMaster.stdout 2><LOG_DIR>/AppMaster.stderr 14/02/20 22:51:00 INFO distributedshell.Client: Submitting application to ASM 14/02/20 22:51:00 INFO impl.YarnClientImpl: Submitted application application_1392907840296_0001 to ResourceManager at /0.0.0.0:8032 14/02/20 22:51:01 INFO distributedshell.Client: Got application report from ASM for, appId=1, clientToAMToken=null, appDiagnostics=, appMasterHost=N/A, appQueue=default, appMasterRpcPort=0, appStartTime=1392907860335, yarnAppState=ACCEPTED, distributedFinalState=UNDEFINED, appTrackingUrl=192.168.0.102:8088/proxy/application_1392907840296_0001/, appUser=chris
...
14/02/20 22:51:08 INFO distributedshell.Client: Application has completed successfully. Breaking monitoring loop 14/02/20 22:51:08 INFO distributedshell.Client: Application completed successfully
And the results are:
1 2 3
$ cat logs/userlogs/application_1392907840296_0001/*/stdout Thu Feb 20 14:51:05 UTC 2014 Thu Feb 20 14:51:06 UTC 2014